Circuits for AI
Edge AI/LLM Systems Co-Design
Energy-efficient accelerators and HW/SW co-design for edge AI and LLM inference under tight power, latency, and area constraints.
EdgeLLM Transformer Accelerator [1]
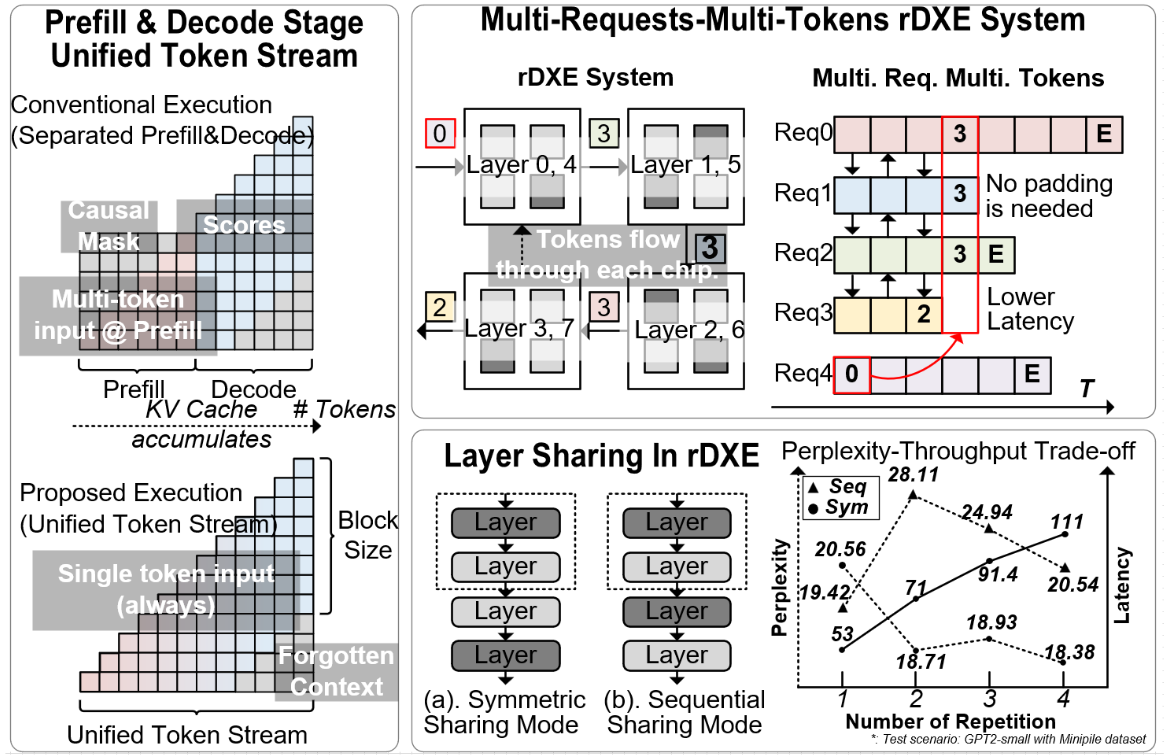
Large language models (LLM) have permeated many aspects of our lives. Edge deployment has attracted strong interest from industry, driven by benefits in privacy, reliability, and cost. However, there are three main challenges.
- EMA-Limited Prefill and Decode Efficiency
- Bottlenecks in Multi-Request Inference
- Underutilization from Non-MAC Operations
We design a rDXE (ring-based Decoder eXecution Engine) system to tackle these challenges.
Our tapeout in Intel 16nm.

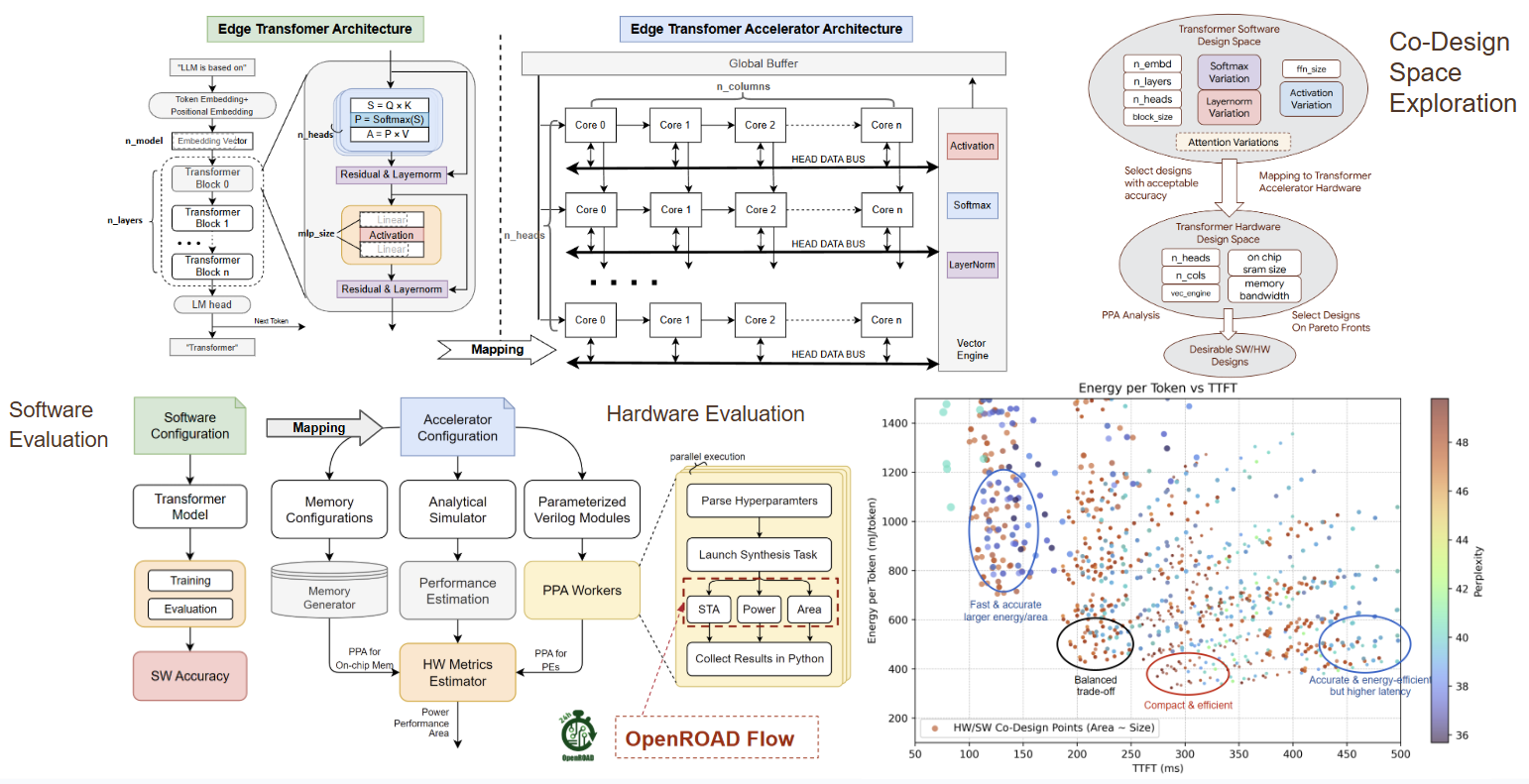
Transformer SW-HW Co-Exploration
We co-explore edge Transformer architectures and a custom systolic-array accelerator to balance accuracy, time-to-first-token, energy, and area. For each candidate design, we map model parameters onto hardware configurations and evaluate performance, timing, power, and area with an analytic loop and OpenROAD. The resulting design space highlights trade-offs between speed, efficiency, and area to guide practical choices.
[1] G. Tao, J. Luo, S. Liu, A. Li, G. Kielian, K. Lei, Q. Zhang, D. Sylvester, M. Saligane, "A 11.16μJ/token Edge LLM Accelerator with Scalable Ring-based Configuration for Token-wise Pipelining in 16nm FinFET," IEEE Custom Integrated Circuits Conference (CICC) 2026.